Goal
- 연관 배열과 해시 테이블에 대한 이해
- 해시 테이블 관련 용어에 대한 이해
- 해시 함수를 구현해본다.
- 해시 충돌 처리 기법에 대해 몇 가지 설명할 수 있다.
해시 테이블(hash table)이란?
연관 배열(associative array)의 일종으로, 키(key)를 값(value)에 매핑할 수 있는 자료구조이다.
*연관 배열 vs 해시 테이블
연관 배열(associative array) : (키, 값) 쌍으로 구성된 추상 자료형으로 연관 배열에서 키는 유일한 값을 갖는다.
맵(map), 사전(dictionary)으로 불리기도 한다.
참고) https://en.wikipedia.org/wiki/Associative_array
구현 형태
해시 테이블 관련 용어
해시 테이블
연관 배열(associative array)의 구현 형태로, 해시, 해시 함수, 해싱, 버킷, 슬롯 등의 개념을 포함한다.
버킷(bucket)과 슬롯(slot)
해시 테이블에서 값은 버킷(bucket)과 슬롯(slot)으로 이루어진 형태의 테이블에 저장된다.
(이 테이블 자체를 버킷이라고 표현 하기도 함)
- 버킷(bucket) : 여러개의 슬롯을 저장하는 레코드 형태의 자료 구조로, 버킷의 갯수는 고정적이다.
- 슬롯(slot) : 해시와 매핑되는 값이 저장되어 있는 공간으로, 하나의 버킷 안에는 여러개의 슬롯이 존재할 수 있다. 슬롯은 하나 이상의 값을 저장할 수 있다.
해시(hash)
해시 함수(hash function)를 통해 얻는 값으로, 해시를 인덱스 또는 주소로 삼아 직접 접근이 가능하도록 한다.
(해시 값(hash value) 또는 해시 코드(hash code)라고도 한다.)
해시를 이용해서 해시 테이블의 버킷(bucket) 또는 슬롯(slot)에 접근한 뒤 탐색, 삽입, 삭제 등의 연산을 수행한다.
해시 함수(hash function)
임의의 길이의 데이터(key)를 고정된 길이의 데이터(해시)로 매핑하는 함수.
이 때, 매핑 전 원래 데이터의 값을 키(key), 매핑 후 데이터의 값을 해시(hash)라고 한다.
즉, key -> hash로 매핑 시켜주는 함수를 해시함수라 한다.
좋은 해시 함수의 조건
- 해시 값이 해시 테이블 주소 영역 내에서 고르게 분포 되어야 한다.
- 충돌이 적어야 한다. (중복값 최소화)
- 계산이 빨라야 한다.
해싱(hashing)
key -> hash -> value로 값을 탐색하는 과정으로, 해시 함수를 사용한 탐색을 가리켜 해싱이라고 한다.
해싱은 매우 빠른 검색을 위한 용도로 많이 사용된다.
평균적으로 O(1)의 탐색 시간을 갖는다. (충돌이 많을 경우 더 느려질 수 있다.)
해싱의 성능은 해시 함수의 성능과 해시 테이블의 크기에 따라 달라진다.
해시 충돌(hash collision)
해시함수가 서로 다른 두 개의 키에 대해 동일한 해시값을 내는 경우로,
h(k1) == h(k2) 성립하면 해시 충돌이 발생 했다고 한다. (h : 해시함수. k1, k2 : 임의의 key값)
이때, k1, k2 를 동의어(synonym)라 한다.
해싱을 할 때, 해시 충돌이 발생할 수 있기 때문에 해시 충돌에 대한 처리가 반드시 필요하다.
매우 큰 집합(ex : 가능한 모든 사람 이름)을 비교적 작은 크기의 공간(hash table size)에 매핑 시킬 때, 해시 충돌이 발생할 수 있다. 이 경우 table size가 입력 가능한 집합의 크기보다 작기 때문에 완전히 해시 충돌을 피할 수 있는 알고리즘은 존재하지 않는다. (비둘기집 원리)
다음 그림은 해싱 충돌이 발생하는 상황을 나타낸다.

John Smith, Sandra Dee에 대한 해시값이 동일하기 때문에 해시 충돌이 발생했다고 할 수 있다.
해시 함수 구현 방법
해시 함수는 여러가지 형태로 구현될 수 있기 때문에 그 중 몇가지 방법에 대해 알아보자.
(입력 크기 또는 자료형 등에 따라서 다르게 구현될 수 있다.)
<참고>
division method
mod연산을 사용하는 방법으로, 탐색키를 특정 값으로 나눈 나머지를 주소로 결정
h(k) = k mod M
M은 대게 소수이면서 2의 거듭 제곱 수와 먼 수를 사용하면 좋다고 알려져 있다.
multiplication method
2진수 연산을 빠르게 하기 위한 방법으로 다음과 같은 형태로 사용될 수 있다.
h(k)=(kA mod 1)×m
이때, m은 2의 거듭 제곱 형태로 표현되며 쉬프트 연산(>>, <<)을 사용하여 곰셈 연산을 빠르게 수행한다.
mid-squares
탐색키를 제곱한 다음, 중간 몇 비트를 취해 주소로 결정
folding
탐색키를 여러 부분(section)으로 나누어 모두 더한 값을 해시 주소로 사용하는 방법.
(숫자를 접어서 표현한 것처럼 보여서 folding이라고 부른다.)
마지막 부분을 제외한 section은 동일한 크기로 나눈다.
폴딩 종류
- shfit folding : 탐색키를 여러 부분으로 나눈 것을 ADD 또는 XOR 연산하는 방법
- boundary folding : 이웃한 부분의 값을 거꾸로 취한 뒤 계산하는 방법

해시 충돌 처리 방법
- Chaining : 해시 충돌이 일어나면 연결 리스트 형태로 이어 나가 충돌을 처리하는 기법
- Open adressing : 해시 충돌이 일어나면 다른 버켓에 데이터를 삽입하는 방식
1. Chaining
chain처럼 연결되어 이어나간다는 의미로, 해시 충돌이 발생했을 경우 연결 리스트 형태로 이어 나간다.
충돌이 일어날 경우, 노드를 연결 시켜주시키 때문에 크기 제한에 있어서 자유롭다.
Open hashing 이라고도 한다. (Open adressing과 혼동 주의)
크기 제한 없이 Open 되어 있다는 의미에서 open hashing 이라고 부르는 듯하다.

시간 복잡도 분석
최악의 경우 : O(n)
평균 적인 경우 : O(α) (α : 버킷당 평균 요소의 개수)
2. Open adressing
다른 주소에 데이터를 저장할 수 있도록 허용한다는 취지에서 open addressing이라고 하는듯 하다.
Closed hashing 이라고도 한다.
Open hashing과 반대로 Slot 개수가 정해져 있어서(닫혀있는 형태라) Closed hashing이라고 하는듯하다.
종류
- 선형 조사법(Linear probing) : 해시충돌 시 고정폭(ex : 1칸)을 옮겨 다음 버킷을 조사하는 방법
- 이차 조사법(Quadratic probing) : 해시충돌 시 제곱수 만큼 건너 뛰어 버킷을 조사하는 방법(1,4,9,...)
- 이중 해싱(Double hashing) (or rehashing) : 충돌 시 다른 해시 함수를 적용하는 방법
<참고> Open Addressing 분석
Open Addressing 키의 삭제
해싱의 성능 분석
해싱의 성능 분석하기 위해서 적재 비율(load factor)을 사용한다.
α = n/M (α : 적재 비율, n : 저장된 항목 개수, M : 버킷의 개수)
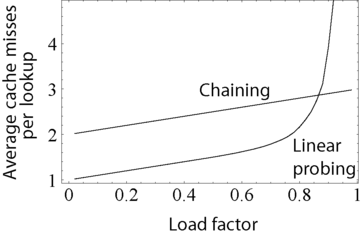
적재 비율이 커짐에 따라 해시 테이블의 성능이 나빠지고 사용 함수에 따라 동작하지 않을 수도 있다.
따라서, 사용 함수에 따라 적재 비율을 특정 값 이하로 유지하는 것이 좋다.
ex) Linear probing : 0.5이하로 유지, Quadratic probing : 0.7 이하로 유지
성능을 위해서 또는 공간 낭비를 적게 하기 위해서 적당한 적재 비율을 유지하는 것이 좋다.
Load factor에 따른 성능 비교
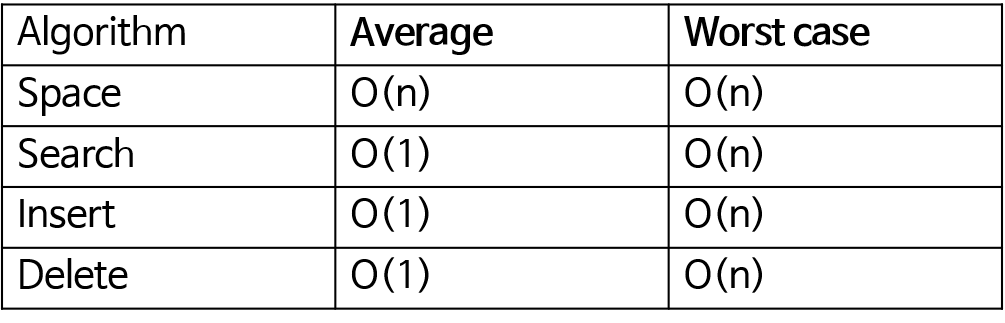
해시 테이블 시간 복잡도
해시 테이블의 장단점
장점
- 삽입, 삭제, 탐색 시간이 빠르다.
단점
- 순서가 보장되지 않는다.
References
http://www.mydeveloperconnection.com/p/introduction-to-hash.html
https://en.wikipedia.org/wiki/Hash_function#Hashing_integer_data_types
https://en.wikipedia.org/wiki/Hash_table
'알고리즘 > 자료구조' 카테고리의 다른 글
| AVL Tree (0) | 2020.07.02 |
|---|---|
| 힙(heap) (0) | 2020.07.02 |
| 가중치 그래프(Weighted Graph), 최소 신장 트리(MST) (0) | 2020.06.21 |
| 트리(Tree) (1) | 2020.06.21 |
| 그래프(Graph) (0) | 2020.06.18 |


